 Ampereのコードネームを冠する2020年最新のNVIDIA次世代GPU、最上位ウルトラハイエンドモデル「GeForce RTX 3090」を筆頭に「GeForce RTX 3080」や「GeForce RTX 3070」が正式発表
Ampereのコードネームを冠する2020年最新のNVIDIA次世代GPU、最上位ウルトラハイエンドモデル「GeForce RTX 3090」を筆頭に「GeForce RTX 3080」や「GeForce RTX 3070」が正式発表
Ampereのコードネームを冠する2020年最新のNVIDIA次世代GPU”GeForce RTX 30”シリーズから、最上位ウルトラハイエンドモデル「GeForce RTX 3090」、ハイエンドモデル「GeForce RTX 3080」、高コスパなミドルハイクラス「GeForce RTX 3070」が正式発表されました。
「GeForce RTX 3090」はGA102-300コアが使用されておりCUDAコア数は10496、GPUコアクロックはベース1395MHz、ブースト1695MHzです。VRAMには従来よりも高速な19.5GbpsのGDDR6Xメモリを24GB容量搭載しています。典型的なグラフィックボード消費電力を示すTGPは350Wに設定されており、PCIE補助電源として8PIN×2以上を要求します。
「GeForce RTX 3090」の希望小売価格は1499ドルからで、9月24日より発売が予定されています。なお国内のメーカー想定価格は23万円ほどとのこと。
GeForce RTX 30シリーズはビデオ出力としてHDMI2.1を新たにサポートしており、8K/60FPSや4K/120FPSのディスプレイ表示に対応します。HDMI2.1が策定する可変リフレッシュレート同期機能もサポートしており、LG製OLEDテレビの2020年モデルなどと組み合わせることで、4K/120Hz環境においてG-Sync Compatibleを使用できます。
「GeForce RTX 3090」の性能については、LG製OLEDテレビなどと組み合わせて8Kゲーミングにも対応できるとのこと。ControlやDeath Strandingのような重量級の超高画質PCゲームでもDLSSを併用することによって8Kゲーミングに対応できるようです。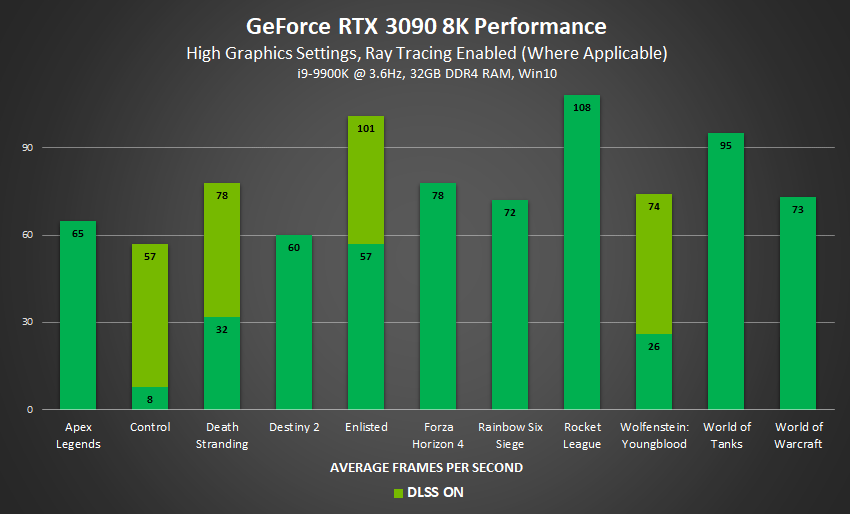
「GeForce RTX 3090」はNVLinkの高速帯域を利用したマルチGPU機能SLIをサポートしています。RTX 30シリーズではRTX 3090のみがNVLink SLIに対応します。またRTX 20シリーズとはNVLink端子の形状が変わっているので、新たに対応ブリッジを用意する必要があります。ただし近年では対応する新作ゲームがほぼないので、競技ベンチマーク向け感が……。
GeForce RTX 3090 / 3080を使う時のPCIE補助電源の繋ぎ方。ケーブルの先端が二股でもできる限り1ケーブル1コネクタで接続する。Seasonic先生とのお約束っ!!
この繋ぎ方でもOCPとかでシステム落ちする場合は、素直に電源ユニットの買い替えを推奨。https://t.co/BrKecpFwco pic.twitter.com/jaEXCJVtDT
— 自作とゲームと趣味の日々 (@jisakuhibi) September 2, 2020
「GeForce RTX 3080」はGA102-200コアが使用されておりCUDAコア数は8704、GPUコアクロックはベース1440MHz、ブースト1710MHzです。VRAMには従来よりも高速な19.0GbpsのGDDR6Xメモリを10GB容量搭載しています。典型的なグラフィックボード消費電力を示すTGPは320Wに設定されており、PCIE補助電源として8PIN×2以上を要求します。
「GeForce RTX 3080」の希望小売価格は699ドルからで、9月17日より発売が予定されています。なお国内のメーカー想定価格は11万円ほどとのこと。
「GeForce RTX 3070」はGA104-300コアが使用されておりCUDAコア数は5888、GPUコアクロックはベース1500MHz、ブースト1725MHzです。VRAMには14.0GbpsのGDDR6メモリを8GB容量搭載しています。典型的なグラフィックボード消費電力を示すTGPは220Wに設定されており、PCIE補助電源として8PIN×1以上を要求します。Founders Editionは8PIN×1ですが、各社AIBモデルの多くは8PIN+6PINや8PIN×2を要求しています。
「GeForce RTX 3070」の希望小売価格は499ドルからで、10月より発売が予定されています。なお国内のメーカー想定価格は8万円ほどとのこと。
「GeForce RTX 3080」は一般的なPCゲームにおいて前世代同クラスのGeForce RTX 2080に対して最大で2倍の性能を発揮し、レイトレーシング&DLSSによって4K/60FPSのPCゲーミングに対応します。
一方、下位モデルの「GeForce RTX 3070」は前世代最上位モデルGeForce RTX 2080 Tiと同等の性能を実現しながら、販売価格は半分を下回る499ドルからに設定されており、コストパフォーマンスが非常に優れた製品です。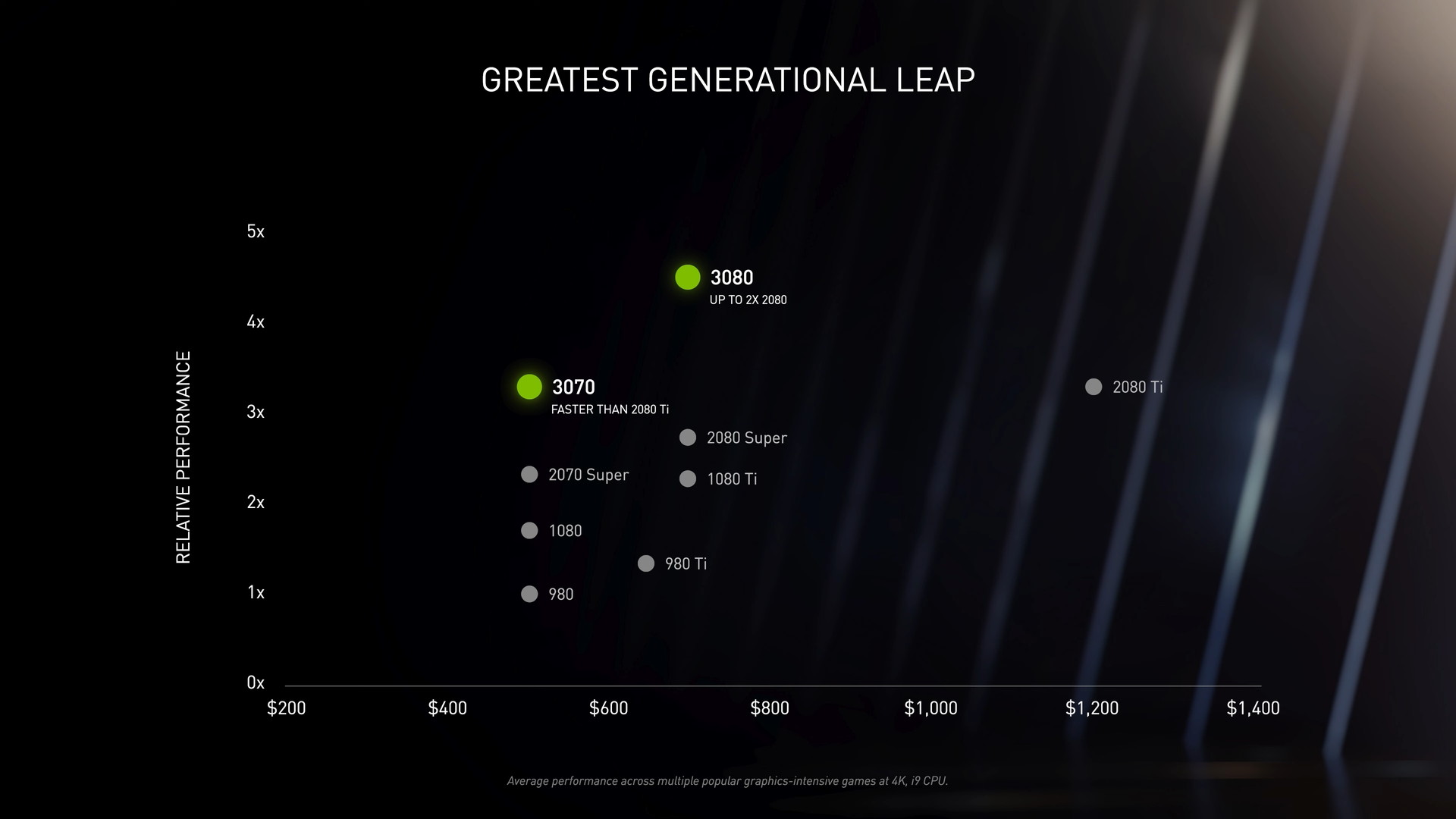
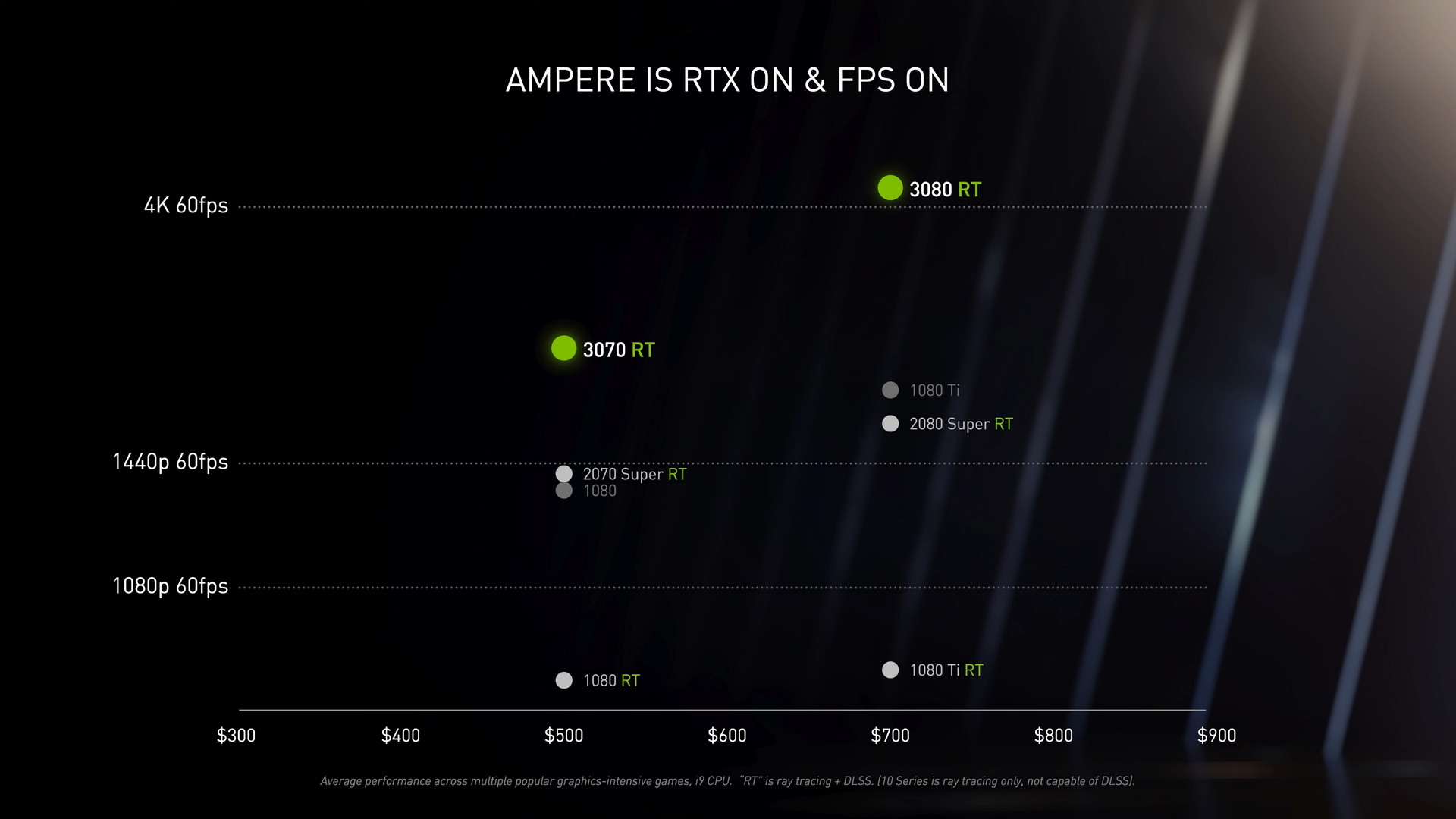
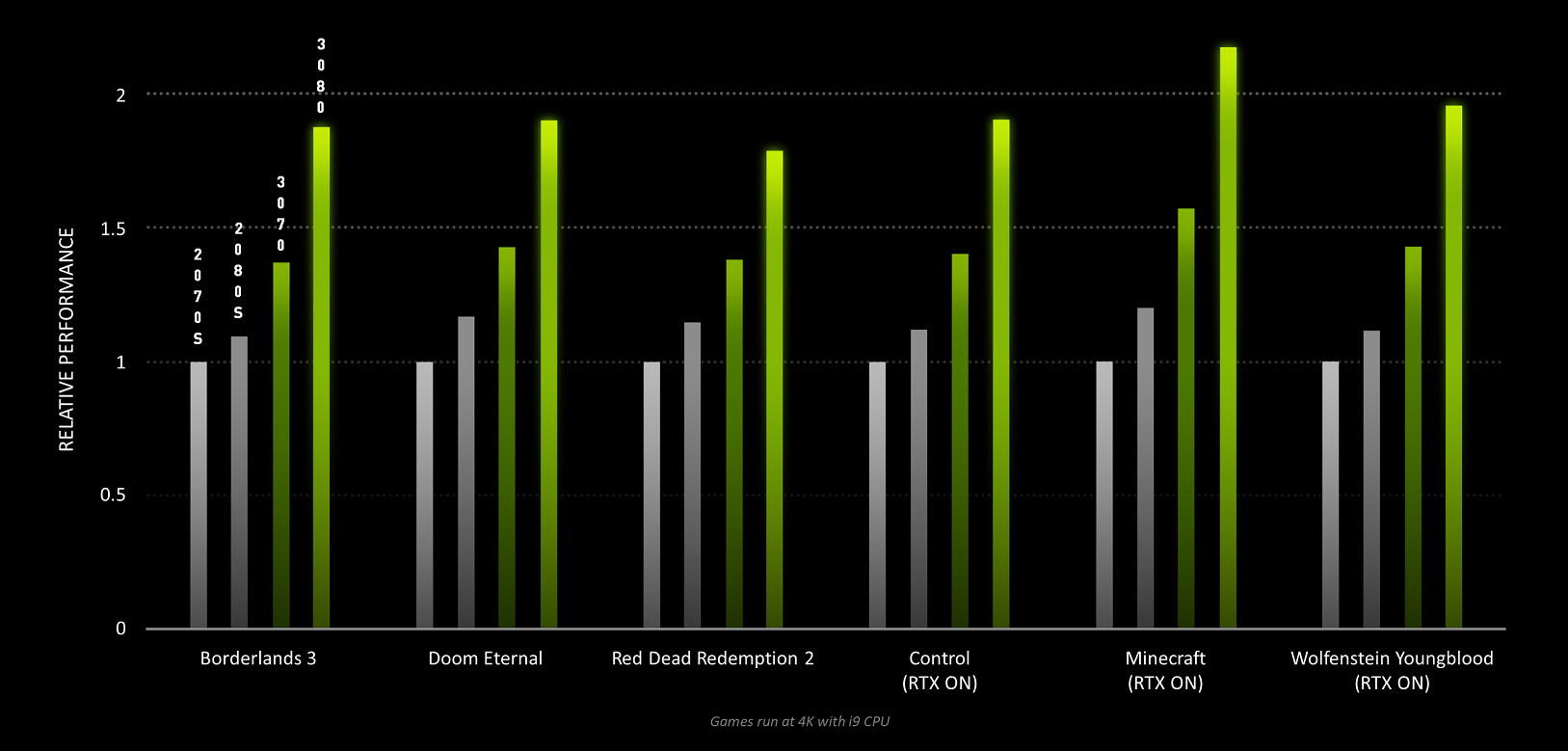
GeForce RTX 30シリーズに採用されるAmpereアーキテクチャは、NVIDIA向けにカスタムされた最新のSamsung製8nmプロセスによって製造され、世界最速のMicron製GDDR6Xメモリをグラフィックメモリに採用しています。またグラフィックボードの接続帯域として、現在主流なPCIE3.0x16への下方互換もありますが、同規格の2倍の帯域を実現する次世代規格PCIE4.0x16をネイティブサポートしています。
GeForce RTX 30シリーズのCUDAコア数の爆増とも関係すると思われるのですが、CUDAコア群のストリーミングマルチプロセッサ(Streaming Multiprocessors:SMs)のFP32スループットが、Turing世代と比較してAmpereでは2倍に向上しています。
ただしCUDAコア数の爆増と比較して性能の伸びが小さいので、CPUにおけるマルチスレッディングのような仮想的な話なのではないか?、と適当に予想していたところ当たらずとも遠からずでした。
この件についてはRedditの公式Q&Aで回答されています。
前世代TuringではFP32とINT32を同時に実行できる(データパスが独立に用意されている)ことがアーキテクチャとしての新しい特徴でした。Ampereでは2つのデータパスのうち、INT32用のデータパス上にINT32の実行ユニットだけでなく、FP32の実行ユニットも乗せています。なので1クロックで同時に実行できるFP32の最大数が2倍になっているという話です。
【公式Q&Aより抜粋】
- Could you elaborate a little on these doubling of CUDA cores?
- How does it affect the general architectures of the GPCs?
One of the key design goals for the Ampere 30-series SM was to achieve twice the throughput for FP32 operations compared to the Turing SM. To accomplish this goal, the Ampere SM includes new datapath designs for FP32 and INT32 operations. One datapath in each partition consists of 16 FP32 CUDA Cores capable of executing 16 FP32 operations per clock. Another datapath consists of both 16 FP32 CUDA Cores and 16 INT32 Cores. As a result of this new design, each Ampere SM partition is capable of executing either 32 FP32 operations per clock, or 16 FP32 and 16 INT32 operations per clock. All four SM partitions combined can execute 128 FP32 operations per clock, which is double the FP32 rate of the Turing SM, or 64 FP32 and 64 INT32 operations per clock.
Doubling the processing speed for FP32 improves performance for a number of common graphics and compute operations and algorithms. Modern shader workloads typically have a mixture of FP32 arithmetic instructions such as FFMA, floating point additions (FADD), or floating point multiplications (FMUL), combined with simpler instructions such as integer adds for addressing and fetching data, floating point compare, or min/max for processing results, etc. Performance gains will vary at the shader and application level depending on the mix of instructions. Ray tracing denoising shaders are good examples that might benefit greatly from doubling FP32 throughput.
従来では『CUDAコア数 = FP32実行ユニットの数』とカウントしていたので、同じく単純にFP32実行ユニットの数をカウントするとAmpereアーキテクチャのGeForce RTX 30シリーズでは、CUDAコア数が2倍に爆増します。(今後、CUDAコア数の表記で物議をかもしそうな気が……)
Ampereの単純性能(理論的な、理想的な性能)は前世代Turingと比較して(RTX 3080とRTX 2080の比較)、シェーダー(CUDAコア)性能が2.7倍、レイトレーシングコア性能が1.7倍、テンサーコア性能が2.7倍に向上しているとのこと。
ただし実際のアプリケーションではINT32も使用されるので、実性能を見るとGeForce RTX 30シリーズは単純に2倍の性能にはならず、INT32/FP32混合データパスの使用状態に応じて、性能の伸び幅(Performance gains)が変動します。
Ampereはレイトレーシングを使用するゲームや3Dレンダリング等のクリエイティブソフトなどの実アプリケーションにおいても、前世代Turingと比較して1.5~2倍のパフォーマンスを発揮します。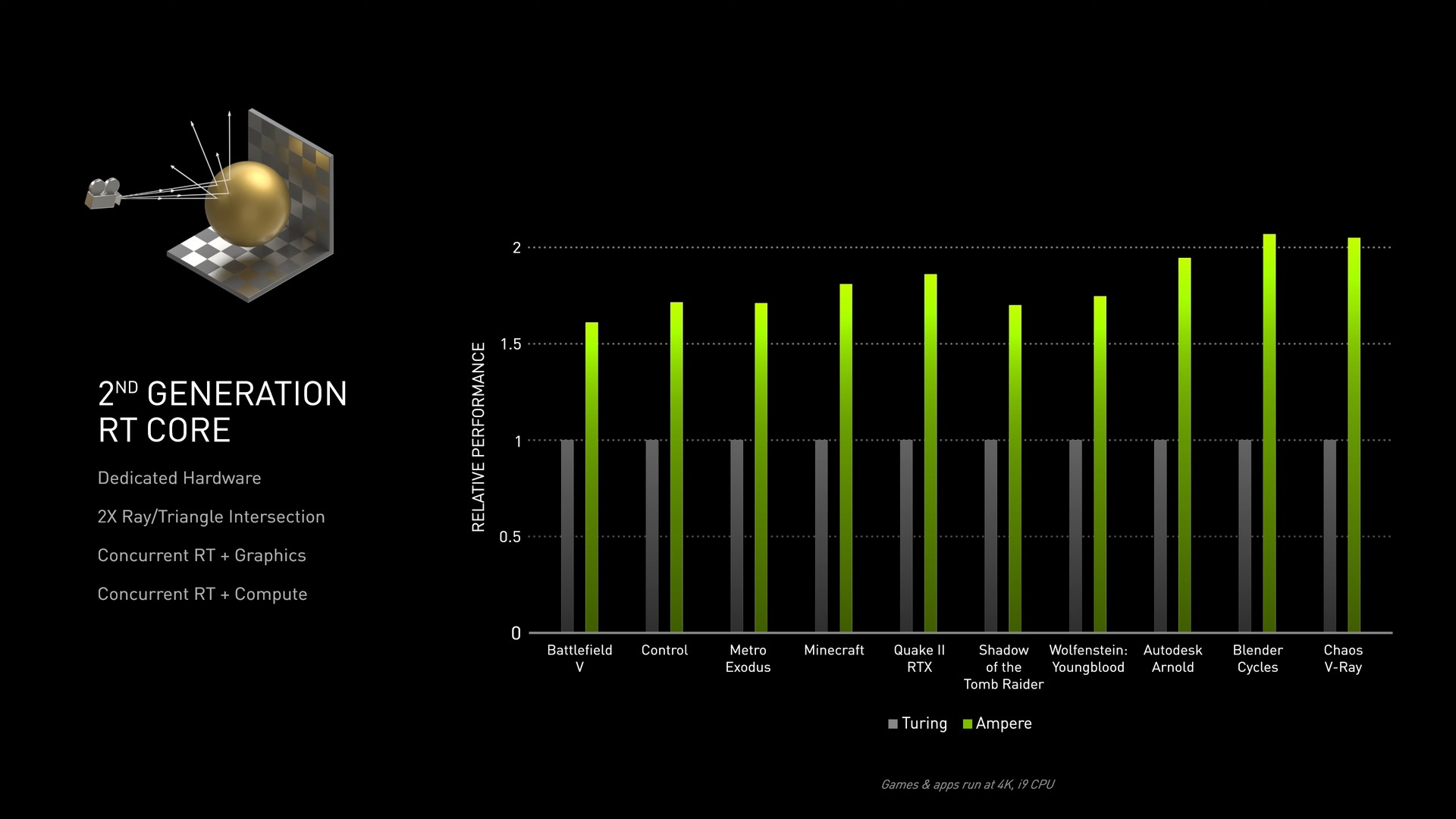
また最新の8nmプロセスによって製造されるAmpereことGeForce RTX 30シリーズは、12nmプロセスで製造された前世代GeForce RTX 20シリーズと比較して1.9倍のワットパフォーマンスを実現しています。
GeForce RTX 30シリーズの諸機能について、前世代RTX 20シリーズとの大きな違いとして、8K/60FPS映像を取り扱えるHDMI2.1に対応したのは上で解説した通りですが、それに伴ってハードウェアデコーダのNVDecが第5世代にアップデートしています。第5世代NVDecでは、8Kなど超高解像度映像に使用されるAV1コーデックのデコードに対応しています。
ゲーム実況などリアルタイム配信・録画において好評を博したNVEncについてはRTX 20シリーズと同じく第7世代が採用されています。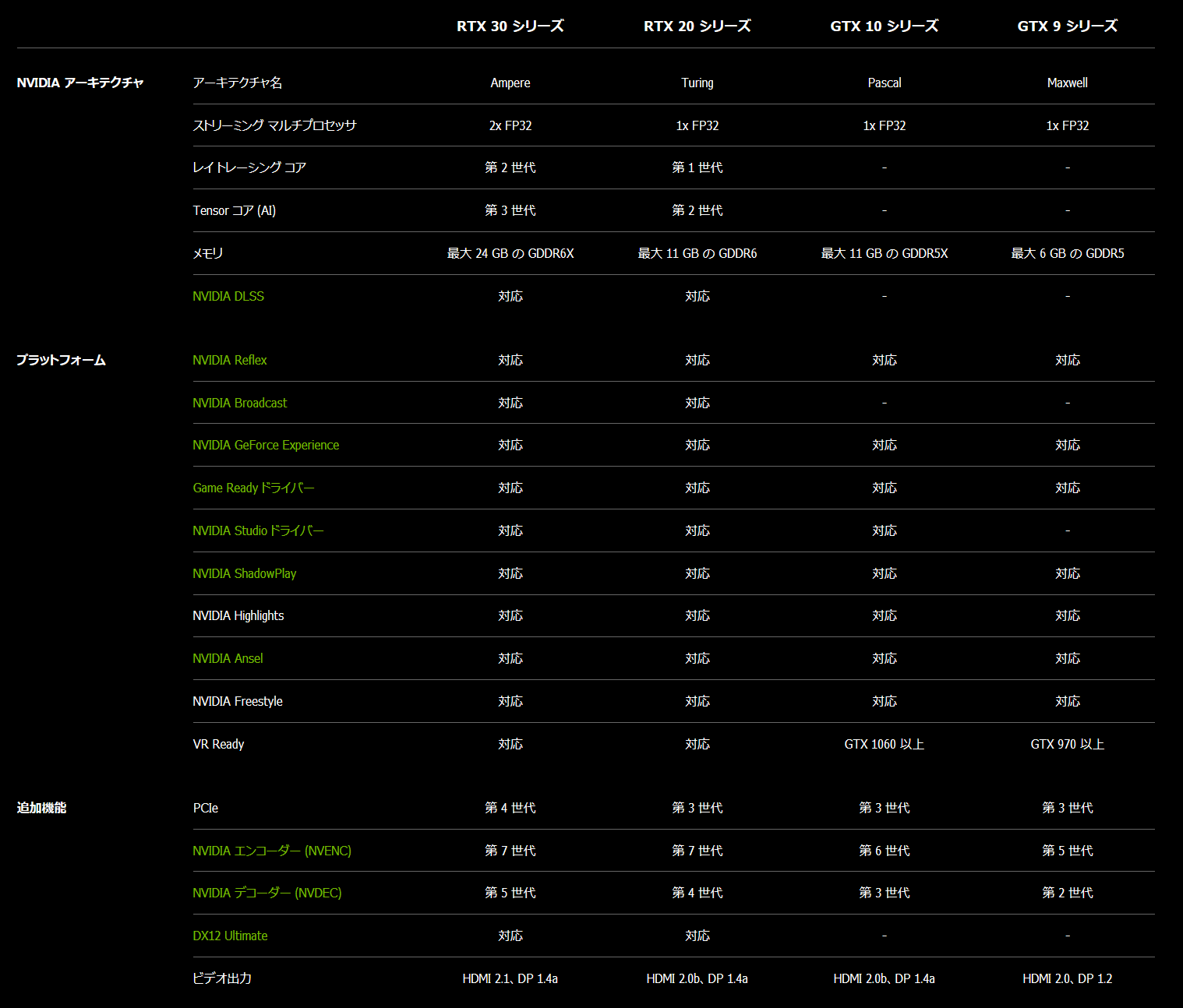
GeForce RTX 30シリーズと同時に、強化された低遅延化機能「NVIDIA Reflex」がリリースされています。従来のドライバのみの手法ではなく、ゲー エンジンの動作をレンダリングに合わせて完了するように調整することでさらに低遅延化を実現します。
公式ブログポスト:https://www.nvidia.com/ja-jp/geforce/news/reflex-low-latency-platform/#reducing-system-latency-with-nvidia-reflex
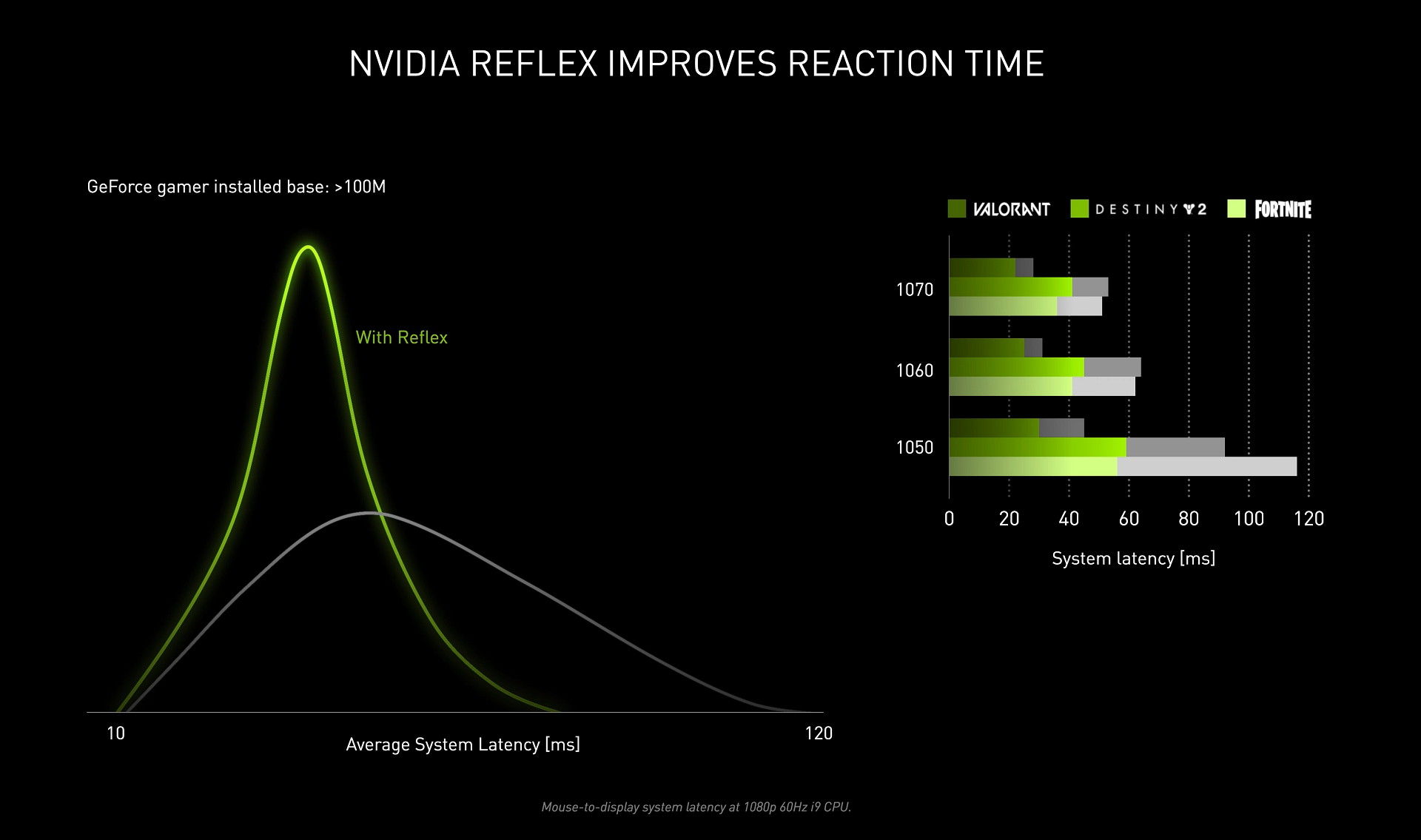
低遅延化機能としては「NULL(NVIDIA Ultra Low latency)」が提供されていましたが、NVIDIA Reflexはゲーム側の対応が必要になるものの、NULLよりもさらに低遅延化を実現しています。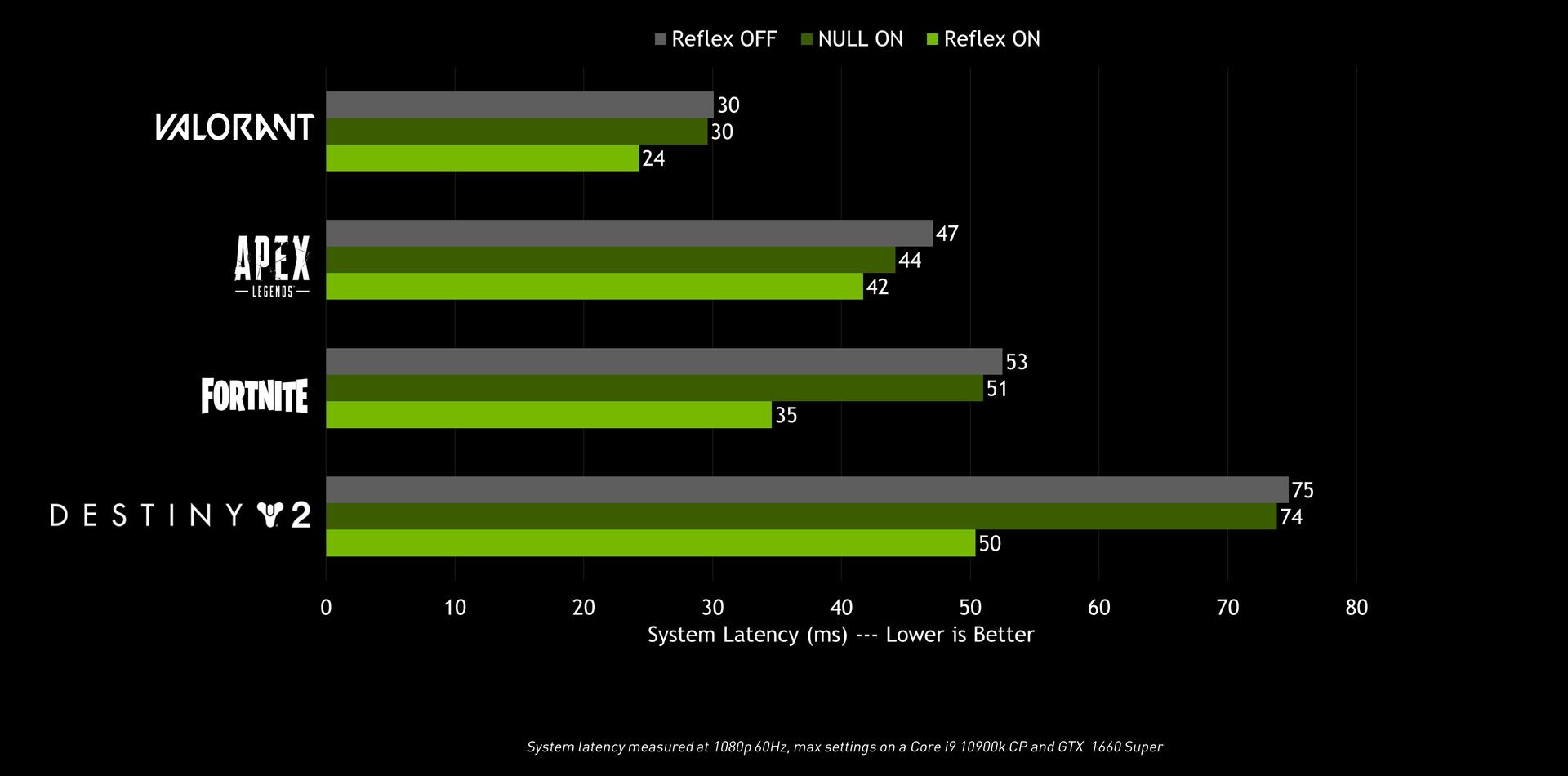
NVIDIA ReflexはGeForce GTX 900シリーズ以降のNVIDIA製GPUでサポートされますが、GeForce RTX 30シリーズにおいて最も効果を発揮するとのこと。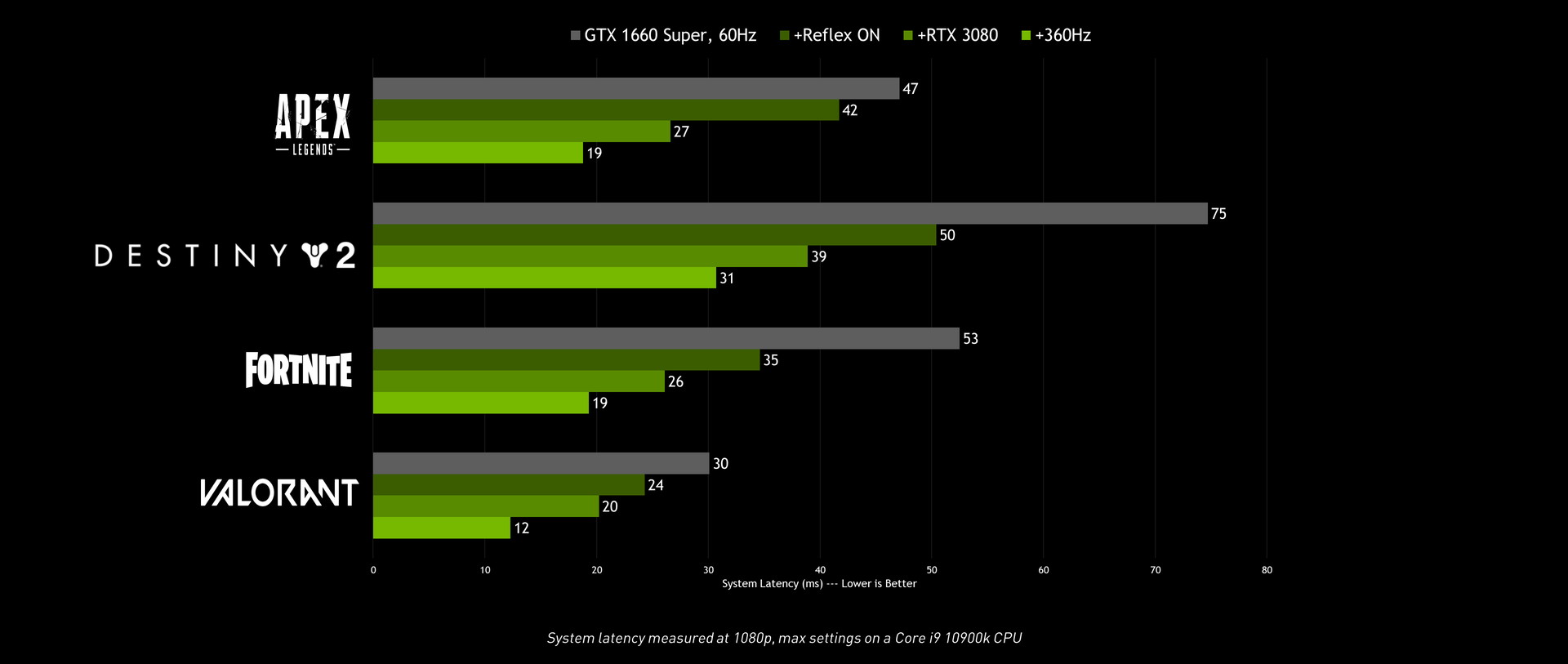
RTX30シリーズ:https://www.nvidia.com/ja-jp/geforce/graphics-cards/30-series/
RTX 3090:https://www.nvidia.com/ja-jp/geforce/graphics-cards/30-series/rtx-3090/
RTX 3080:https://www.nvidia.com/ja-jp/geforce/graphics-cards/30-series/rtx-3080/
RTX 3070:https://www.nvidia.com/ja-jp/geforce/graphics-cards/30-series/rtx-3070/
| GeForce RTX 30XXシリーズのスペック早見表 | |||||
| 価格 | CUDA コア数 |
VRAM 容量/速度 |
TGP | 性能の概要 | |
| RTX 3090 | 1499ドル~ | 10496 | 24GB 19.5Gbps |
350W | 8Kゲーミングにも対応 |
| RTX 3080 | 699ドル~ | 8704 | 10GB 19Gbps |
320W | RTX 2080の2倍 |
| RTX 3070 | 499ドル~ | 5888 | 8GB 14Gbps |
220W | RTX 2080 Tiよりも高速 |
| TITAN RTX (Turing) |
2499ドル | 4608 | 24GB 14Gbps |
280W | |
| RTX 2080 Ti | 999ドル~ | 4352 | 11GB 14Gbps |
260W | |
| RTX 2080 SUPER |
699ドル~ | 3072 | 8GB 15.5Gbps |
250W | |
| NVIDIA GeForce RTX 3090/3080/3070 詳細スペック比較 | ||||
| GPU名 | RTX 3090 |
RTX 3080 | RTX 3070 |
RTX 2080 Ti |
| GPUダイ | GA102-300 | GA102-200 | GA104-300 | TU102-300 |
| 製造プロセス | Samsung 8nm |
Samsung 8nm | Samsung 8nm | 12nm FinFET |
| CUDAコア数 | 10496 | 8704 | 5888 | 4352 |
| TMU/ROP | -/- | -/- | -/- | 272/88 |
| ベースクロック | 1395MHz | 1440MHz | 1500MHz | 1350MHz |
| ブーストクロック (FE) |
1695MHz | 1710MHz | 1725MHz | 1545MHz (1635MHz) |
| メモリ | 24GB GDDR6X | 10GB GDDR6X | 8GB GDDR6 | 11GB GDDR6 |
| バス幅 | 384-bit | 320-bit | 256-bit | 352-bit |
| メモリクロック | 4875 MHz | 4750 MHz | 3500 MHz | 3500 MHz |
| 有効メモリクロック | 19500 MHz | 19000 MHz | 14000 MHz | 14000 MHz |
| メモリ帯域 | 936 GB/s | 760 GB/s | 448 GB/s | 616 GB/s |
| PCIEレーン | PCIE4.0x16 | PCIE4.0x16 | PCIE4.0x16 | PCIE3.0x16 |
| マルチGPU | NVLink SLI | – | – | NVLink SLI |
| TGP(TDP) | 350W |
320W | 220W | 250W (FE:260W) |
| 補助電源 | 8PIN×2~ | 8PIN×2~ | 8PIN×1~ | 8PIN×2~ |
| 対応ビデオ出力 | DP1.4 HDMI2.1 |
DP1.4 HDMI2.1 |
DP1.4 HDMI2.1 |
DP1.4 HDMI2.0 USB Type-C |
| 登場時期 | 20年9月24日 |
20年9月17日 | 20年10月 | 18年9月 |
| 価格 | 1499ドル~ | 699ドル~ | 499ドル~ | 999ドル~ FE:1199ドル |
記事が参考になったと思ったら、ツイートの共有(リツイートやいいね)をお願いします。
Ampereのコードネームを冠する2020年最新のNVIDIA次世代GPU、最上位ウルトラハイエンドモデル「GeForce RTX 3090」を筆頭に「GeForce RTX 3080」や「GeForce RTX 3070」が正式発表。詳細スペックや性能を解説。https://t.co/p9OL08uOZw pic.twitter.com/Xu42nNxXuh
— 自作とゲームと趣味の日々 (@jisakuhibi) September 1, 2020

・RTX 3080搭載のおすすめゲーミングBTO PCを徹底比較!
・RTX 3090搭載のおすすめBTO PCを徹底比較! 【TITAN RTX更新に最適】

関連記事
・おすすめグラボまとめ。予算・性能別で比較。各社AIBモデルの選び方
・グラフィックボードのレビュー記事一覧へ
・予算と性能で選ぶオススメのゲーミングモニタを解説
・PCモニタ・ディスプレイのレビュー記事一覧へ
・おすすめBTO PCまとめ。予算・性能別で比較。カスタマイズ指南も
・【できる!個人輸入】米尼でおすすめなEVGA製グラボのまとめ











コメント